
Ako ChatGPT počíta znaky v texte? Analýza a techniky na optimalizáciu výstupov
Určite ste už počuli, ako sa SEO-čkár alebo kopíčka rozčuľovali nad tým, že ChatGPT nedodržal nastavený limit počtu znakov. „Veď to je hlúposť!“ hovorí, „Prečo mi to nevychádza presne, keď to mám nastavené na 150 znakov?!“ Aj keď je to frustrujúce, ide o zaujímavý jav, ktorý vychádza zo spôsobu, akým jazykový model (aký používa napr. aj ChatGPT) generuje text.
Poďme sa teda pozrieť na to, prečo sa to deje a ako sa tomu dá predísť. Pri hľadaní riešení sme opísali možné prístupy a detailne sa venovali základnej technike, ktorú sme otestovali v rámci série RankMaster3000.
Spôsob generovania odpovedí v ChatGPT
ChatGPT generuje text na základe veľkých jazykových modelov (GPT), ktoré fungujú na princípe predikcie ďalšieho slova na základe predchádzajúceho kontextu. Tieto modely nepracujú priamo so slovami, ale s tokenmi – najčastejšie predstavujú špeciálne zakódované segmenty textu pričom 1 slovo môže byť rozdelené do viacerých tokenov. Princíp tokenizácie využívajú prakticky všetky veľké jazykové modely (aj napr. Gemini a ďalšie).
Preto sa môže zdať, že model nedodržiava pôvodné „znaky“ či medzery, keďže generovanie výsledku vychádza z tokenizovanej podoby textu a nie z čisto vizuálneho zápisu, na aký sme zvyknutí pri čítaní.
To teda môže viesť k nedodržaniu požiadaviek na dĺžku generovaných odpovedí.
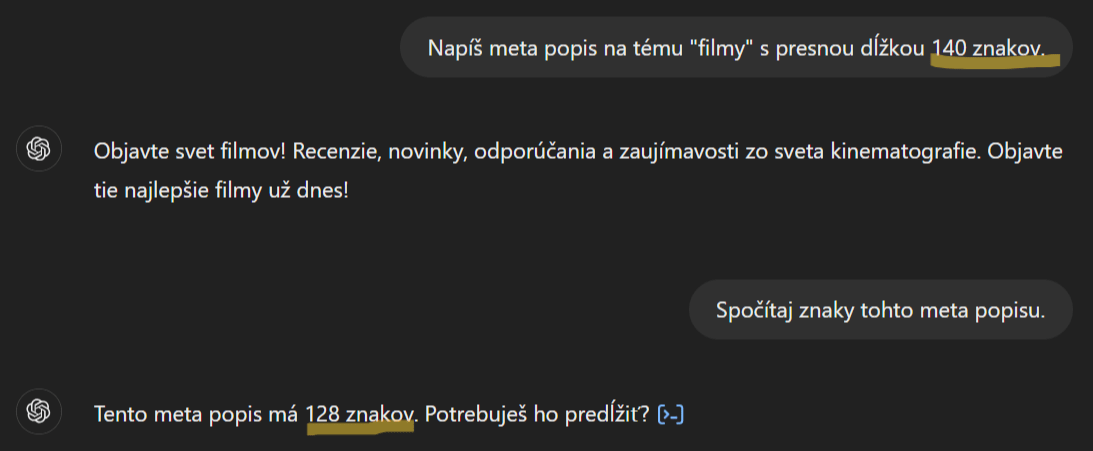
Obrázok 1: Príklad častého problému s počtom znakov (zdroj: chatgpt.com)
Čo je teda token?
Token označuje základnú jednotku textu, s ktorou model pracuje. Môže ísť o časť slova, celé slovo alebo dokonca iba o znak (napríklad interpunkčné znamienko). Základným pravidlom je, že 1 token má približne 4 znaky alebo 0,75 slova pre anglický text.
Ako tokeny fungujú?
- Rozdelenie textu na tokeny: Keď jazykový model spracováva text, rozdelí ho na tokeny pomocou špecifického algoritmu nazývaného tokenizácia.
- Spracovanie tokenov: Model vykonáva výpočty na úrovni týchto tokenov, aby pochopil kontext a vygeneroval odpoveď.
- Limit tokenov: AI modely, ako ChatGPT, majú obmedzenie na počet tokenov, ktoré môžu spracovať v jednom dopyte (vrátane vstupu a výstupu). Napríklad model GPT-4 má limit okolo 8 000 alebo 32 000 tokenov, v závislosti od verzie.
Prečo sú tokeny v interakcii s jazykovými modelmi dôležité?
- Efektivita: Tokenizácia umožňuje jazykovému modelu pracovať efektívnejšie, pretože spracováva text v menších jednotkách.
- Cena a výkon: Používanie modelu je často spoplatnené podľa počtu spracovaných tokenov, takže tokeny ovplyvňujú aj cenu za jeho využívanie.
- Presnosť: Dobrá tokenizácia zabezpečuje, že jazykový model lepšie porozumie textu, čo zvyšuje kvalitu jeho odpovedí.
Príklad počítania tokenov
Nástroj OpenAI Tokenizer umožňuje používateľom vidieť, ako jazykový model rozdelí zadaný text na jednotlivé tokeny. Napríklad reťazec „tokenization“ sa rozloží na morfémy ako „token“ a „ization“.

Obrázok 2: Príklad počítania tokenov (zdroj: platform.openai.com)
Ako znížiť pravdepodobnosť nedodržania limitu textu
Technika približovania
Je to najzákladnejšia technika, ktorú využíva väčšina používateľov, aj keď o tom nemusia vedieť. Funguje to tak, že v rámci promptu zadáte obmedzenie na určitý rozsah znakov alebo slov, ktoré vám následne pomáha priblížiť sa k želanej dĺžke odpovede.
Tento prístup síce nezabezpečí úplné obídenie tokenových limitov, ale je pomerne jednoduchý a efektívny pre menšie objemy dát, ktoré si nevyžadujú exaktnú presnosť. No a keďže je táto technika najčastejšie používaná, skúsme sa pozrieť na jej kvalitu výstupu a možnosti optimalizácie.
Analýza techniky približovania v praxi
V prvej analýze sme vykonali test siedmich typov promptov, každý na vzorke 200 odpovedí (celkovo 1400 odpovedí). Chceli sme zistiť, ako dobre model (GPT-4o) dodržiava stanovený rozsah generovaných textov a aké metódy tvorby promptov dosahujú najvyššiu účinnosť.
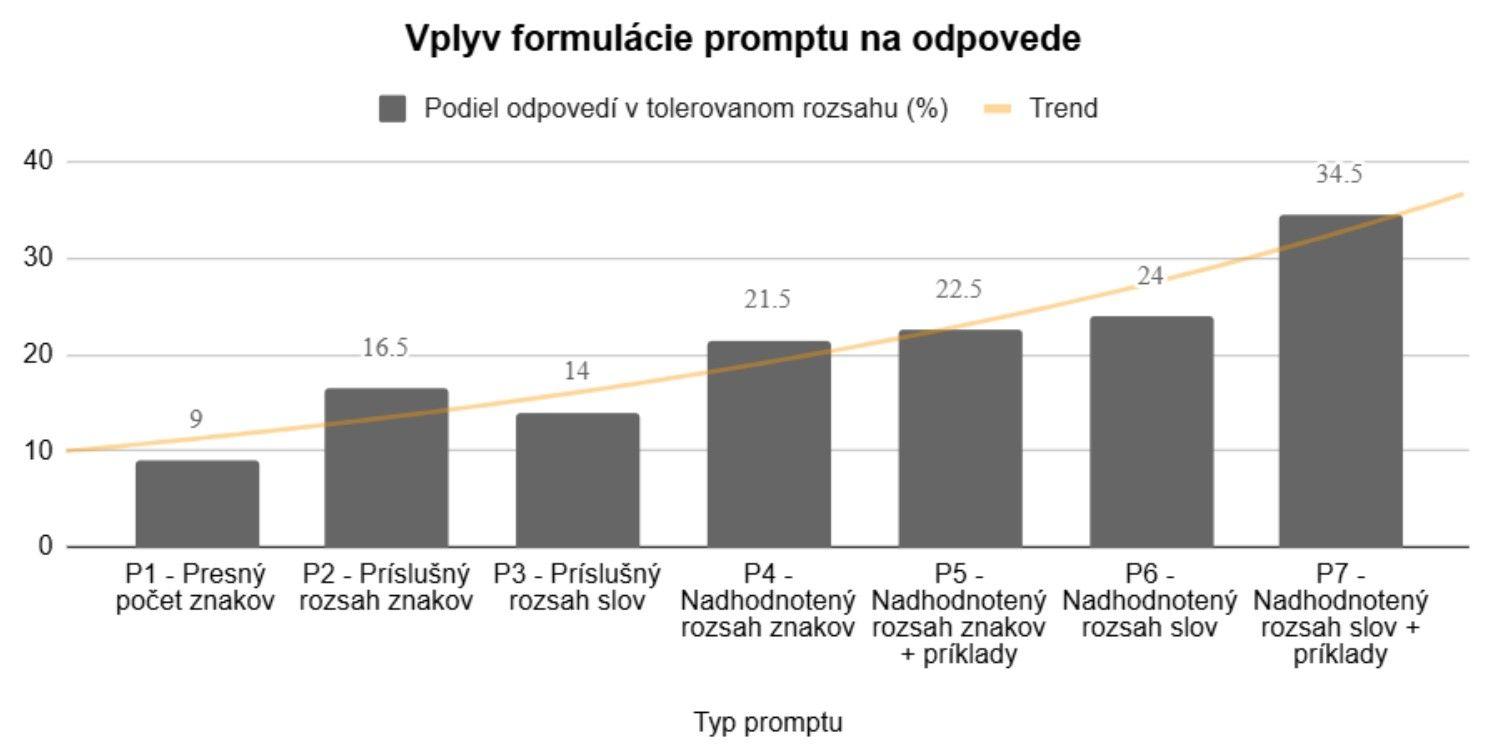
Graf 1: Porovnanie štýlu zadania promptu a trend odpovedí v tolerovanom rozsahu (zdroj: vlastné spracovanie)
Graf ukazuje, že najlepšie výsledky dosiahol prompt s nadhodnoteným rozsahom slov a príkladmi (P7), ktorý dosiahol najvyšší podiel odpovedí v tolerovanom rozsahu. Celkový trend naznačuje, že použitie slov, kombinácia širšieho rozsahu a konkrétnych príkladov môžu viesť k vyššej presnosti odpovedí v porovnaní s prísnejšími alebo menej špecifickými zadaniami.
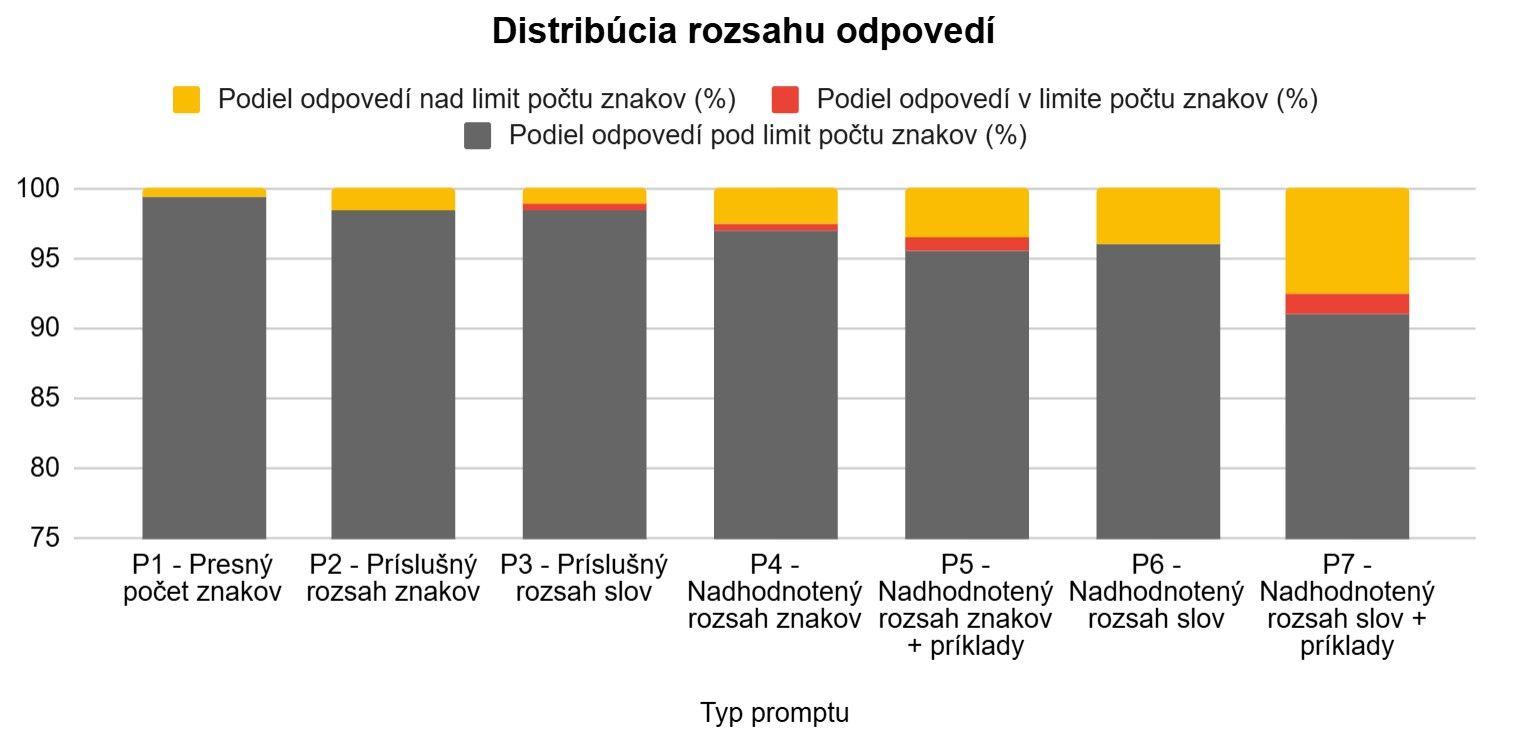
Graf 2: Spôsob distribúcie rozsahu odpovedí od požadovaného limitu (zdroj: vlastné spracovanie)
Ďalší graf naznačuje, že prompt s nadhodnoteným rozsahom slov a príkladmi (P6) môže mierne podporovať vyšší podiel odpovedí nad limitom znakov. Naopak, striktne definované zadania (P1) smerujú odpovede skôr pod stanovený limit. Napriek tomu sú dané rozdiely relatívne malé pre závery. S istotou však vieme povedať, že model výrazne podhodnocuje limity znakov.
Počas našej analýzy sme si všimli zaujímavý jav. S rastúcim počtom jednorázovo požadovaných odpovedí na prompt klesal podiel odpovedí v tolerovanom rozsahu.
Preto sme vytvorili druhú analýzu na piatich promptoch s príslušným rozsahom znakov (celkovo 255 odpovedí). Náš vstup v modeli (GPT-4o) sme rozdelili na prompty podľa množstva jednorázových dopytov (teda požiadali sme o 5, 25, 50, 75 alebo 100 odpovedí naraz). Sledovali sme, či zvyšujúcim sa množstvom požiadaviek v jednom prompte dochádza k poklesu presnosti a konzistentnosti generovaných textov.
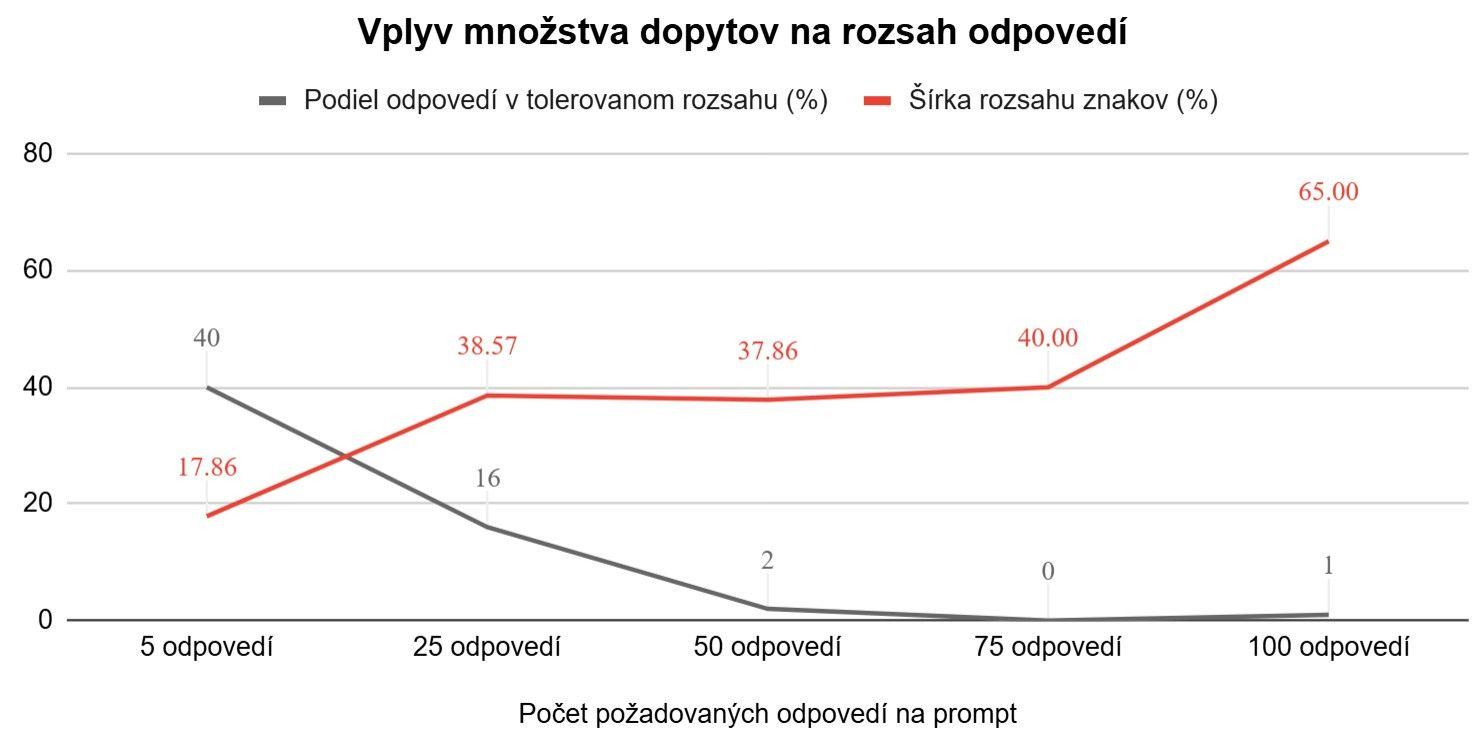
Graf 2: Dopad množstva požiadaviek na presnosť odpovedí (zdroj: vlastné spracovanie)
Ako vidieť na grafe, odchýlka bola najvýraznejšia pri jednorázovom požiadaní o 100 odpovedí, kde šírka rozsahu znakov dosahuje maximum a podiel odpovedí v tolerovanom rozsahu zostáva takmer nulový.
Tento jav naznačuje, že vyšší počet odpovedí môže viesť k väčšej variabilite výsledkov a zároveň k nižšej konzistentnosti voči pôvodným požiadavkám. Dôvodmi tohto javu môžu byť obmedzená kapacita modelu na udržanie konzistencie, rastúca komplexita variácií odpovedí a kumulatívny efekt malých odchýlok v interpretácii promptu.
7 základných pravidiel techniky približovania pri promptovaní
Pri formulovaní požiadavky (promptu) nezabudnite:
- Použiť slová namiesto znakov pri rozsiahlejších textoch: Pri textoch nad 90 znakov je efektívnejšie riadiť generovanie textov pomocou počtu slov, pretože slová lepšie zachytávajú význam a štruktúru odpovede. Pri kratších textoch, kde je potrebná vyššia presnosť, odporúčame nechať limit na úrovni rozsahu znakov, aj keď je to v praxi menej precízna alternatíva.
- Nadhodnotiť cieľovú dĺžku textu: Z našich skúseností rozptyl vygenerovaného obsahu býva častejšie pod zadefinovanou hranicou, preto odporúčame nastaviť si cieľovú dĺžku o niečo vyššie ako maximálnu požadovanú hodnotu textu, ktorý chceme získať.
- Určiť optimálnu odchýlku: Pre flexibilitu je dobré nastaviť odchýlku okolo 15 – 30 % od požadovanej dĺžky. Tento širší priestor umožňuje generovanému textu variabilitu, pričom stále dodržiava požiadavky na kvalitu. Presné hodnoty odchýlky si najlepšie určíte prostredníctvom testov odpovedí, keďže výsledky môžu závisieť od konkrétneho typu požiadavky a jazykového modelu.
- Poskytnúť konkrétny príklad: Na lepšie pochopenie rozsahu odporúčame nielen určiť ChatGPT požadovanú dĺžku v slovách či znakoch, ale aj objasniť, ako tento rozsah funguje pri generovaní odpovedí a ilustrovať to poskytnutím vhodného príkladu textu požadovaného rozsahu.
- Rozdeliť väčšie požiadavky na menšie časti: Ako uvádza aj Andrew Best, zadávanie veľkého množstva odpovedí v jednom prompte vedie k poklesu presnosti a konzistentnosti generovaných textov. Model má obmedzenú schopnosť udržať kvalitu pri spracovaní veľkých objemov výstupov naraz, čo zvyšuje variabilitu a riziko odchýlok. Odporúčame preto väčšie zadania rozdeľovať na menšie celky, aby sa zachovala vyššia miera presnosti a konzistencie výsledkov. Príklad z praxe – ak chcete v realite 50 meta popisov, vašu požiadavku nastavte na 25 a zopakujte ju ešte raz.
- Zvýšiť počet odpovedí: Pravdepodobnosť, že dostanete požadovanú kvalitu odpovede, sa zvyšuje, ak požiadate o väčší počet variantov odpovedí v ďalšej komunikácii. Pri limitovaní na základe počtu slov alebo znakov požiadajte o 2 – 5- násobne viac odpovedí než potrebujete.
- Možnosť vyhodnocovať v tabuľkových programoch: Výstupy s väčším množstvom vygenerovaných variantov požadujte vo forme jednoduchej tabuľky. Tú následne prekonvertujte napríklad do tabuľkového programu, kde dáta pohodlne a spoľahlivo očistíte. Aj keď v ukážkach používame počítanie slov či znakov priamo v jazykovom modeli, nespoliehajte sa naň. Počítanie slov a znakov je prísne deterministická operácia, no ChatGPT pracuje na báze modelovania jazyka a málokedy presne spočíta jednotlivé znaky či slová na prvýkrát. Majte však na pamäti, že táto technika nie je ideálna na spracovanie veľkého objemu dát.
Príklad aplikovania pravidiel techniky približovania
Výstup v rozhraní ChatGPT
Pamätáte si náš príklad z úvodu? Skúsime to ešte raz s aplikovanou technikou približovania. Naším hlavným cieľom bolo získať jeden meta popis, ktorý sa čo najviac priblíži k ideálnej dĺžke 140 znakov.
Prompt sme nastavili tak, aby pracoval so slovami namiesto znakov. Cieľovú dĺžku sme mierne nadhodnotili, aby sme znížili riziko odchýlok pod požadovaný rozsah. Ten sme jasne definovali a doplnili ho konkrétnym príkladom. Zároveň sme si nechali vygenerovať viac variantov odpovedí, aby sme mali širší priestor na výber toho najlepšieho výsledku.
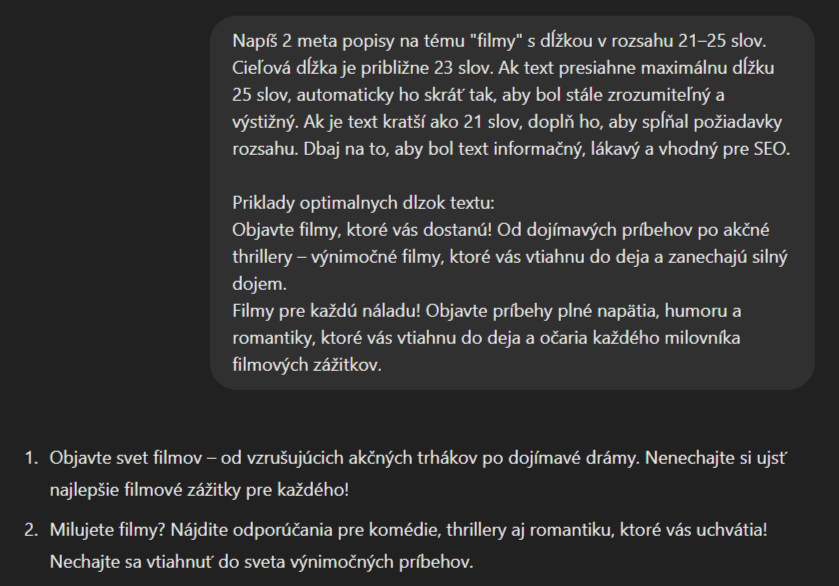
Obrázok 3: Použitie promptu na základe techniky približovania (zdroj: chatgpt.com)
Podľa WordCounteru má prvý popis 130 znakov a druhý popis 144 znakov. To znamená, že v našom tolerovanom rozsahu (130 – 150 znakov) sme plne trafili rozsah a teraz už len vyberieme ten obsahovo najzaujímavejší.
Výstup prevedený do tabuľkovej formy
Ak si vyžiadate výstup priamo vo formáte tabuľky, jednoducho si textové polia skopírujte do tabuľkového programu. My používame napr. Google Sheets.
Ak si tieto textové polia vložíte do stĺpca A, potom zrejme začnú v bunke A2. Do stĺpca B (presnejšie do bunky B2 a nižšie) vám stačí vložiť vzorec na identifikáciu počtu slov:
- “=IF(A2=““;0;COUNTA(SPLIT(A2;“ „)))”
Do stĺpca C (presnejšie do bunky C2 a nižšie) vám stačí vložiť vzorec na identifikáciu počtu použitých znakov:
- “=LEN(A2)”
Následne si vygenerované texty zoradíte a vyfiltrujete preč tie s nevhodným rozsahom textu. To môžete zas vykonať vložením nasledovného vzorca do stĺpca E (napríklad do bunky E2):
- “=FILTER(A2:C, B2:B>=X, B2:B<=Y”
Nezabudnite nahradiť písmená X a Y za číselný rozsah od (X) – do (Y).

Obrázok 4: Selekcia vhodných výstupov v tabuľkovej forme (zdroj: Google Sheets)
Týmto spôsobom dokážete model nasmerovať tak, aby produkoval obsah, ktorý sa čo najviac priblíži požadovanému rozsahu, pričom zohľadníte, že model pracuje s tokenmi. Cieľom je „trafiť sa“ do požadovaného počtu tokenov, čo bude zodpovedať optimálnemu rozsahu textu, ktorý model generuje, pričom minimalizujete odchýlky v počte slov či znakov.
Iné rožsírené techniky
1. Technika cyklu
Nastavíte si automatizovaný cyklus na kontrolu dĺžky odpovede. Využijete pritom kombináciu API a Pythonu na kontrolu a optimalizáciu počtu znakov alebo tokenov v generovaných odpovediach.
Ak odpoveď prekročí stanovený limit, či už dodaním dlhšieho, alebo kratšieho textu, cyklus automaticky upraví požiadavku a vráti upravenú odpoveď. Tento proces sa automaticky opakuje, kým odpoveď nevyhovuje nastaveným kritériám dĺžky. Vtedy cyklus skončí.
Týmto spôsobom viete dodržať, či už stanovený rozsah, alebo aj presný limit. Avšak samotné nastavenie môže byť technicky náročnejšie a samotný cyklus môže spotrebovať výrazne viac tokenov, čo sa môže negatívne odzrkadliť pri celkových kreditoch za nástroj.
Rovnako môžete vykonávať túto techniku aj manuálne. Opakovane budete zadávať požiadavky, kým nedosiahnete text o požadovanej dĺžke. Avšak, tento spôsob je neefektívny a časovo náročný v porovnaní s automatizovaným prístupom.
2. Technika tokenov
Nastavenie parametra max_tokens v prostredí Playground je jedinou presnou možnosťou, ktorú uvádza OpenAI na riadenie dĺžky odpovede. Tento parameter presne obmedzuje maximálny rozsah generovaného textu.
V praxi síce musíte výrazne vyladiť prompt na tokeny, ale často sa stretnete s neželaným skrátením slov alebo viet na konci odpovede. To môže ovplyvniť zrozumiteľnosť a plynulosť textu. Preto odporúčame kombinovať toto nastavenie s technikou cyklu tak, aby ste zbytočne neprečerpávali stanovený limit kreditov.
Porovnanie všetkých techník
| Technika | Výhody | Nevýhody |
| Technika približovania | 1. Jednoduchá implementácia: Rýchle nastavenie bez potreby technických zručností.
2. Flexibilita: Možnosť prispôsobiť prompt rôznym typom textov. 3. Efektívna pre menšie objemy: Dobré výsledky pri jednotlivých výstupoch alebo menších dávkach. |
1. Nedostatočná presnosť: Nedokáže garantovať presné dodržanie limitu.
2. Variabilita výsledkov: Rozdiely v dĺžke odpovedí pri väčšom počte generovaní. 3. Obmedzený pri väčších objemoch: Stráca efektivitu pri väčších dávkach odpovedí. |
| Technika cyklu | 1. Automatizácia procesu: Možnosť nastaviť opakujúce sa úpravy bez manuálneho zásahu.
2. Presné doladenie dĺžky: Výstupy môžu byť veľmi presné v stanovenom limite. 3. Vhodné pre komplexné zadania: Efektívne pre náročné požiadavky na presnosť a veľkosť objemu. |
1. Technická náročnosť: Vyžaduje programátorské zručnosti (API, Python).
2. Vysoká spotreba tokenov: Rýchlejší nárast nákladov pri väčších objemoch textu. |
| Technika tokenov | 1. Presné obmedzenie dĺžky: Garantuje, že text neprekročí stanovený limit. Oficiálny spôsob kontroly dĺžky od OpenAI.
2. Jednoduché nastavenie v Playground: Rýchle nastavenie parametra max_tokens. |
1. Riziko skrátenia viet: Odpovede môžu byť náhle prerušené.
2. Obmedzená flexibilita: Menej vhodné pre rôznorodé textové výstupy. 3. Nutnosť kombinácie s inými technikami: Pre optimálne výsledky je potrebné cyklické overovanie. |
Pochopte systém a prispôsobte svoj prístup
Problém nedodržania obmedzenia počtu znakov alebo slov v ChatGPT spôsobuje fakt, že model pracuje s tokenmi a nie priamo s počtom znakov či slov. Pre lepšie limitovanie dĺžky generovaného textu odporúčame využiť techniky, ktoré umožňujú zvýšiť flexibilitu modelu, a tým pádom aj pravdepodobnosť trafenia sa do požadovaného rozsahu.
Existujú rôzne techniky, ktoré vám pomôžu kontrolovať dĺžku odpovedí. Kým základná technika sa zameriava na zvýšenie pravdepodobnosti úspešnosti, rozšírené techniky ponúkajú aj možnosti automatizácie na dosiahnutie exaktného rozsahu generovaného textu.
Aj keď v súčasnosti nie je možné na 100 % dodržať požiadavky na počet znakov generovaného textu bežným používateľom jazykového modelu, odporúčame použiť základnú techniku približovania, špeciálne vyladenú a otestovanú pre sériu RankMaster3000, ktorá pri dodržaní všetkých spomenutých pravidiel umožňuje dosiahnuť efektívnejšiu kontrolu dĺžky textu.
Pre fajnšmekrov odporúčame využiť cyklus riadený pomocou Pythona.