
Od slov k číslam: Prečo riešime embeddingy
Umelá inteligencia dnes dokáže vyhľadávať informácie, prekladať texty či rozpoznávať obrazy. Pre počítač je to však všetko len séria čísel. Ako teda dokáže „pochopiť“, že dve slová alebo obrázky spolu súvisia?
Riešením sú embeddingy – číselné reprezentácie významu.
Vďaka nim sa texty, obrázky či zvuky dajú previesť do matematického priestoru, kde sa podobné veci ocitajú blízko seba a odlišné ďaleko od seba. Práve tento princíp umožňuje AI pracovať s významom tak, ako to poznáme z praxe, od odporúčaní filmov až po generovanie textu.
Pri príprave článku sme čerpali zo zahraničných zdrojov, ktoré tému embeddingov detailne spracovali. Vybrali sme z nich to najdôležitejšie a spracovali tak, aby bol text praktický a ľahko uchopiteľný.
Čo je vektor a embedding
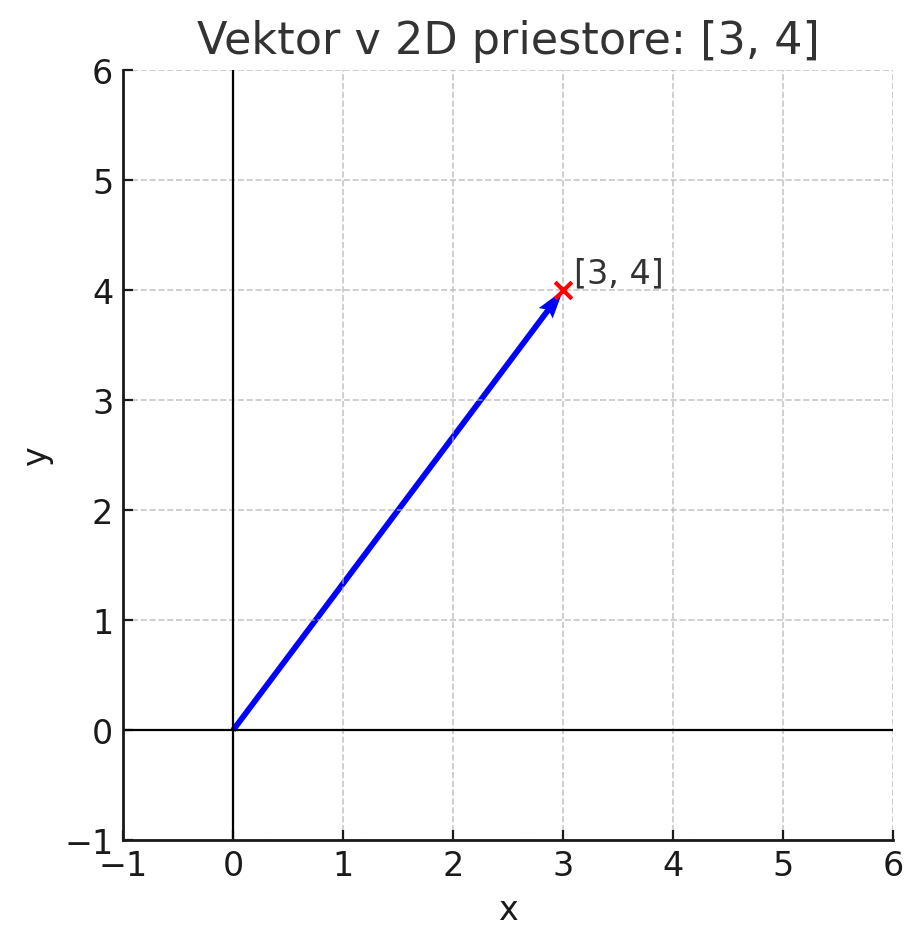
Aby sme pochopili, ako fungujú embeddingy, začnime od pojmu vektor. V matematike je vektor usporiadaný zoznam čísel, ktorý má dĺžku a smer. Najjednoduchšie si ho môžete predstaviť ako šípku v priestore.
Ak máme dvojrozmerný priestor, šípka sa môže nachádzať na súradniciach [3, 4]. Znamená to, že ide 3 jednotky doprava a 4 jednotky hore. V trojrozmernom priestore by mal vektor tri čísla, v desaťrozmernom desať čísel a v moderných AI modeloch sa často používa aj viac ako tisíc čísel.
Na rovnakom princípe fungujú aj embeddingy. Ide o špeciálne vektory v číselnej podobe zachytávajúce význam a vzájomné súvislosti medzi dátami.
Predstavte si ich ako priestor, v ktorom si každý text, obrázok či zvuk nájde svoje miesto. V tomto priestore platí jednoduché pravidlo: čo si je významovo blízke, ocitne sa blízko seba; čo sa líši, zostane ďalej od seba.
Príklad
Predstavme si slová pes a mačka. Aj keď vyzerajú a znejú inak, v skutočnosti majú veľa spoločných vlastností – obe sú domáce zvieratá, majú štyri nohy, žijú s ľuďmi. Preto budú ich embeddingy blízko seba. Naopak, slovo auto má celkom iné vlastnosti (kolesá, doprava, technológia), a preto sa jeho embedding bude nachádzať oveľa ďalej.
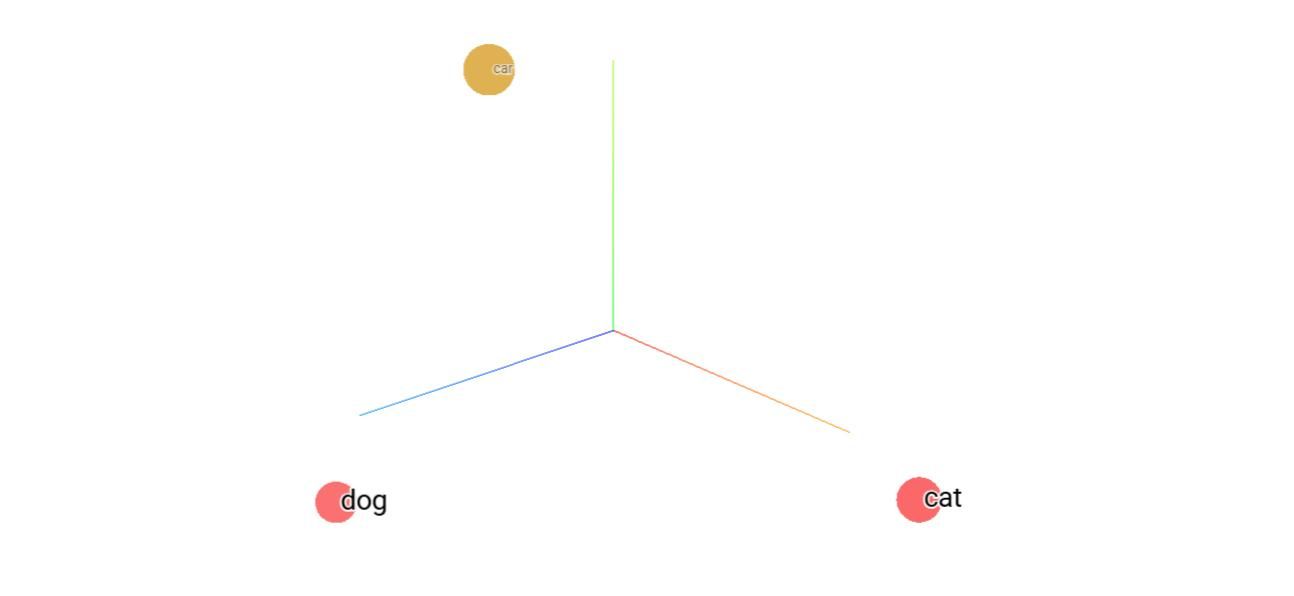
Zdroj: Model Word2Vec, Embedding projector
Čísla vo vektore nepredstavujú písmená ani zvuky. Sú to skryté vlastnosti významu, ktoré model dokáže zachytiť a uložiť do číselnej podoby. Embedding je teda spôsob, ako preložiť slová, obrázky alebo zvuky do formy, ktorej rozumie počítač, a pritom zachovať ich význam.
V texte budeme ďalej používať skrátený pojem embedding, aj keď presnejšie by sme mali hovoriť o vektorovom embeddingu.
Prečo potrebujeme embeddingy
Počítače vedia spracovávať iba čísla. Ak im dáme text, musíme ho premeniť na čísla tak, aby si zachoval význam. Tradičné metódy, ako je napríklad jednoduché priraďovanie čísel jednotlivým slovám, nevedia zachytiť rozdiely medzi slovami ani ich vzťahy.
Vektorové reprezentácie dát prinášajú 3 zásadné výhody:
- Zachytávajú význam: umožňujú pochopiť, že auto a automobil sú to isté, aj keď ide o iné slová.
- Sú efektívne: namiesto obrovských množstiev dát používajú kratšie a hustejšie reprezentácie.
- Sú univerzálne: dajú sa použiť na text, obrázky, zvuk aj iné typy dát.
Ako vznikajú embeddingy
Embeddingy vznikajú v 2 krokoch:
- Tréning (učenie modelu)
- Generovanie (vytvorenie vektora pre nové dáta).
1. Tréning modelu
Na začiatku potrebujeme embeddingový model (špecializovaný algoritmus umelej inteligencie). Tento model sa trénuje na veľkom množstve dát, napríklad na miliónoch viet, článkov či kníh, ktoré nazývame korpus (veľká zbierka textov).
Model sa pri učení riadi tzv. distribučnou hypotézou (slová v podobnom kontexte majú podobný význam). To znamená, že ak sa slová pes a mačka často vyskytujú pri rovnakých slovách ako krmivo či domáce zviera, model sa naučí, že sú si významovo blízke.
Existuje viacero známych embeddingových modelov, ktoré si môžeme predstaviť ako knižnice nástrojov na preklad významu do čísel. Historicky poznáme napríklad:
- Word2Vec (Google, 2013) – učí sa predpovedať, ktoré slová sa objavia spolu. Známa je jeho schopnosť robiť analógie, napríklad: kráľ – muž + žena ≈ kráľovná.
- GloVe (Stanford, 2014) – kombinuje štatistiky výskytu slov a matematické metódy na zachytenie globálnych vzťahov.
- FastText (Facebook, 2017) – rozkladá slová na menšie časti (predpony, prípony, n-gramy), vďaka čomu rozumie aj zriedkavým alebo preklepovým slovám.
Príklad
Na obrázku vidíme ukážku zo slovnej zásoby modelu Word2Vec. Každému slovu je priradený číselný vektor s pevnou dĺžkou (v tomto prípade 200 rozmerov). Tabuľka ukazuje najčastejšie slová v dátach, na ktorých bol model trénovaný, napríklad the, of, and či one.
To, čo je dôležité, sa ale neschováva v samotnom počte výskytov, ale v číselných reprezentáciách vektorov (ukryté za týmito slovami). Práve vďaka nim vie Word2Vec rozpoznať podobnosť alebo vzťahy medzi slovami.
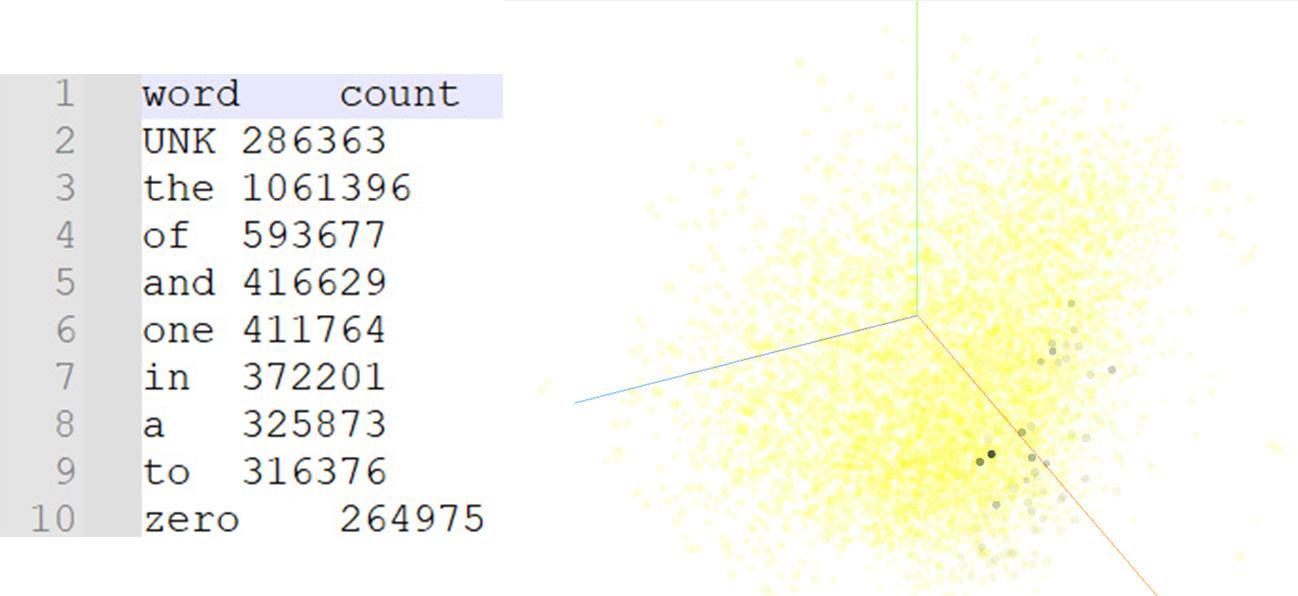
Zdroj: Model Word2Vec, Embedding projector
2. Generovanie embeddingov
Keď je embeddingový model natrénovaný, môžeme doň vložiť nové dáta, slovo, vetu alebo obrázok. Model ich spracuje a vráti nám ich embedding (číselnú reprezentáciu významu). Tento embedding môžeme následne porovnávať s inými embeddingami a zisťovať, nakoľko sú si podobné.
Na akej úrovni sa vytvárajú embeddingy?
Embeddingy môžeme vytvárať na rôznych úrovniach textu, od jednotlivých slov až po celé bloky textu:
- Slovo – staršie modely (napr. Word2Vec, GloVe) priraďovali vektor každému slovu. Nevýhodou bolo, že význam sa nemenil podľa kontextu, takže slovo bank malo rovnaký embedding pre „riečny breh“ aj „finančnú inštitúciu“.
- Veta alebo odsek – moderné modely (napr. BERT, OpenAI embeddings) dokážu vytvoriť vektor pre celú vetu či odsek. Vektor tak odráža kontext, v ktorom sa slová nachádzajú.
- Chunk (blok textu) – pri LLM systémoch (jazykové modely) a metóde RAG (Retrieval Augmented Generation) sa dlhšie dokumenty rozdeľujú na menšie bloky (napr. 200 – 500 slov). Každý blok dostane vlastný embedding, ktorý sa uloží do vektorovej databázy. Pri otázke používateľa sa vytvorí embedding otázky a porovná sa s embeddingami blokov, čím sa nájde najrelevantnejšia časť textu.
Ako sa porovnávajú embeddingy
Až tu začína byť celá vec skutočne zaujímavá. Vytvoriť embedding je jedna vec – preložiť slovo, vetu či obrázok do číselného zoznamu. Ale zábava prichádza vtedy, keď tieto embeddingy začneme porovnávať. Vtedy dokáže AI zisťovať, ktoré pojmy alebo objekty sú si významovo podobné, a ktoré nie.
Najčastejšie sa používajú matematické metódy ako:
- Kosínusová podobnosť (meranie uhla medzi vektormi), čím menší je uhol, tým väčšia podobnosť.
- Euklidovská vzdialenosť (priama vzdialenosť medzi bodmi), čím bližšie sú body v priestore, tým väčšia podobnosť.
Príklad
Vyberme slovo cat (mačka), dog (pes) a car (auto) a zobrazme, ktoré slová sú si v embedding priestore bližšie. Očakávanie je jasné, cat a dog patria do rovnakej kategórie zvierat, zatiaľ čo car je od nich významovo odlišné.
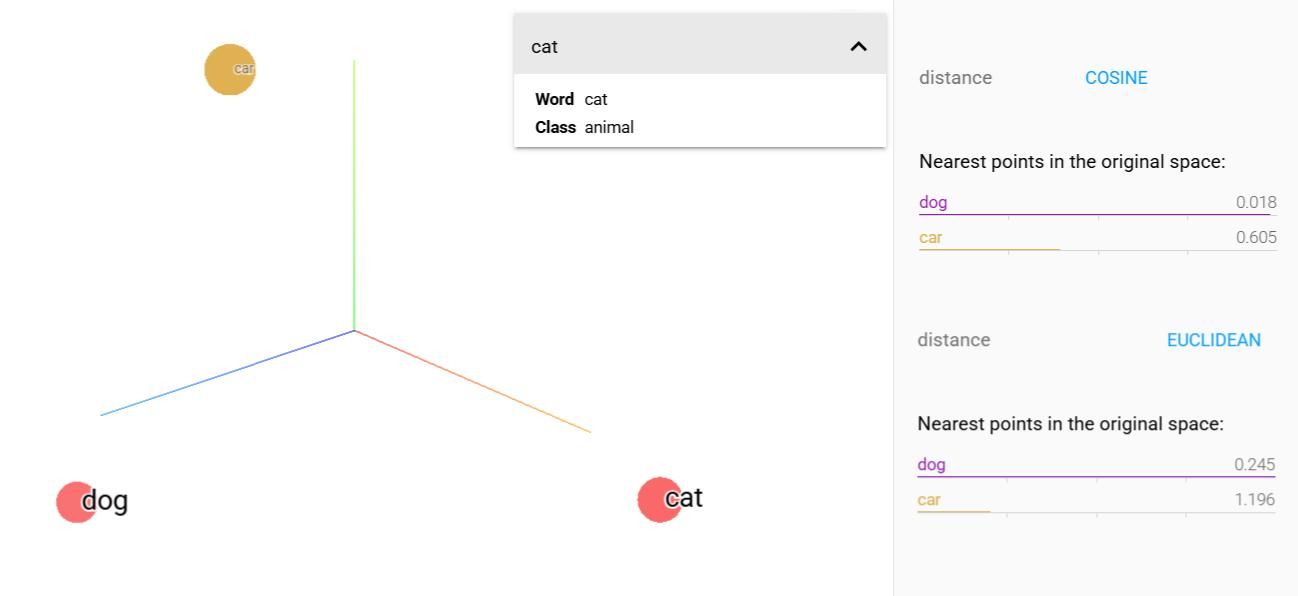
Zdroj: Model Word2Vec, Embedding projector
Kosínusová podobnosť (1. porovnanie): Vidíme, že pre cat je najbližší sused dog (0.018), zatiaľ čo car je výrazne ďalej (0.605). Znamená to, že vektory cat a dog smerujú takmer rovnako, a preto sú si významovo veľmi blízke.
Euklidovská vzdialenosť (2. porovnanie): Aj tu je dog bližšie ku cat (0.245) než car (1.196), ale tentokrát sa meria reálna „dĺžka cesty“ medzi bodmi v priestore, nie uhol medzi nimi.
Kosínusová podobnosť sleduje smer vektorov, teda či ukazujú rovnakým smerom, a preto sa najčastejšie používa pri textových embeddingoch, kde nás zaujíma význam. Euklidovská vzdialenosť meria skutočnú vzdialenosť medzi bodmi a využíva sa tam, kde vektory predstavujú reálne súradnice alebo merania (napr. pri obrazoch či v priestore).
Množstevné spracovanie embeddingov
Tieto matematické metódy sú ako základné pravítka a uhlomery, ktorými meriame, či sú si dva embeddingy blízke. Samé o sebe riešia len malé úlohy, napríklad zistiť, či slová pes a mačka sú si významovo podobné.
Keď však máme milióny embeddingov, tieto metódy sa použijú znova a znova, len vo veľkom. Similarity search, ktoré si predstavíme neskôr, ich kombinuje s inteligentnými algoritmami, ktoré urýchľujú hľadanie. Inými slovami, matematické metódy sú „motor“, ktorý poháňa similarity search.
A práve vtedy sa do hry dostávajú vektorové databázy, ktoré dokážu tieto výpočty robiť rýchlo a vo veľkom. O nich si povieme v nasledujúcej časti.
Vektorové databázy: Pamäť pre embeddingy
Pri porovnávaní dvoch embeddingov stačí vypočítať vzdialenosť alebo uhol. Ale v praxi málokedy pracujeme len s dvomi. Moderné systémy obsahujú tisíce až milióny embeddingov, celé zbierky textov, obrázkov alebo iných dát. A tam už potrebujeme nástroj, ktorý dokáže s takým množstvom rýchlo a efektívne pracovať.
Na to slúžia vektorové databázy (špecializované databázy na ukladanie a vyhľadávanie embeddingov).
Bežná databáza ukladá údaje do tabuliek s riadkami a stĺpcami. Vektorová databáza namiesto toho pracuje s vektormi a je navrhnutá tak, aby vedela okamžite nájsť tie embeddingy, ktoré sú významovo najbližšie k zadanému dopytu. Tento postup sa odborne nazýva similarity search (vyhľadávanie podľa podobnosti).
Príklad
Predstavme si, že máme uložené tisíce recenzií o krmivách pre psy. Ak sa spýtame otázku: „Aké krmivo pre psy je najlepšie?“, systém premení otázku na embedding a odošle ho do vektorovej databázy. Tá porovná embedding našej otázky s embeddingami všetkých recenzií a vráti tie, ktoré sú významovo najbližšie, napríklad recenzie, kde zákazníci najčastejšie spomínajú konkrétnu značku alebo vlastnosti krmiva.
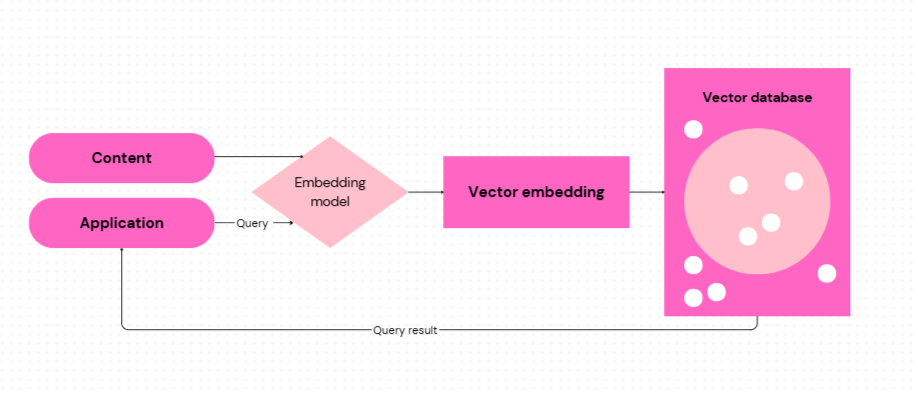
Medzi najznámejšie databázy, ktoré sa dnes používajú, patria FAISS, Pinecone, Chroma a Milvus. Sú to nástroje vyvinuté špeciálne na rýchle vyhľadávanie vo veľkých množinách embeddingov.
Typy embeddingov
Embeddingy sa nepoužívajú iba pre text. Dnes sa využívajú v mnohých oblastiach, pričom každý typ má svoje špecifické využitie:
- Textové embeddingy (slová, vety, dokumenty) – premieňajú text na číselnú reprezentáciu významu. Využívajú ich vyhľadávače, nástroje ako ChatGPT či interné systémy na vyhľadávanie v dokumentoch.
- Obrázkové embeddingy (vektory obrazov) – menia obrázky na číselnú podobu. Používa ich napríklad Google Lens alebo model CLIP od OpenAI, ktoré dokážu nájsť podobné obrázky alebo porovnať obrázok s textovým popisom.
- Zvukové embeddingy (hlas, hudba) – prevádzajú zvukové dáta do čísel. Využívajú ich hlasoví asistenti na rozpoznávanie reči alebo hudobné aplikácie na odporúčanie skladieb a určovanie žánrov.
- Produktové embeddingy (vektory produktov a používateľov) – opisujú produkty aj používateľov. Amazon alebo Netflix takto spájajú podobné produkty či filmy s preferenciami zákazníkov a vytvárajú odporúčania.
- Grafové embeddingy (vzťahy v sieťach) – používajú sa na opis zložitých sietí vzťahov, napríklad v sociálnych sieťach alebo firemných databázach. Pomáhajú pochopiť, kto je s kým prepojený alebo ktoré prvky v sieti spolu úzko súvisia.
- Molekulové embeddingy (chemické zlúčeniny) – premieňajú štruktúru molekúl na číselnú formu. Využívajú sa pri vývoji nových liekov, kde AI hľadá podobnosti medzi známymi látkami a novými kombináciami.
Textové embeddingy v jazykových modeloch
Veľké jazykové modely (LLM), akými sú napríklad ChatGPT alebo Gemini, dokážu na základe svojho tréningu generovať text, odpovedať na otázky či vysvetľovať zložité témy.
LLM však majú prirodzené obmedzenie. Ich „znalosti“ sú dané dátami, na ktorých boli natrénované. Ak sa model stretne s informáciou, ktorá vznikla po jeho tréningu alebo potrebuje detail z veľmi špecifickej oblasti, odpoveď nemusí byť presná.
A práve tu prichádza na scénu Retrieval-Augmented Generation (RAG). Ide o architektúru, ktorá kombinuje jazykový model s vyhľadávaním v externej databáze. Funguje v dvoch krokoch:
- Vyhľadanie informácií pomocou embeddingov: systém prehľadá dokumenty alebo databázu a nájde úseky textu (chunky), ktoré sú významovo najbližšie k položenému dopytu.
- Generovanie odpovede pomocou LLM: vybrané informácie sa poskytnú modelu, ktorý ich zapojí do tvorby odpovede.
Vďaka tomuto postupu dokáže RAG systém spájať silu generatívnej AI s aktuálnymi a spoľahlivými dátami. Výsledkom sú presnejšie, relevantnejšie a dôveryhodnejšie odpovede, než by dokázal poskytnúť samotný jazykový model.
Ako funguje proces RAG v praxi
Celý postup sa dá rozdeliť do 3 hlavných krokov:
- Vyhľadanie relevantných dát
- Vektorizácia dopytu: Keď položíme otázku: „Aké krmivo pre psy je najlepšie?“, systém ju najprv premení na embedding (číselnú reprezentáciu významu).
- Vyhľadanie (retrieval): Tento embedding sa porovná s databázou embeddingov, ktoré boli vytvorené zo zákazníckych recenzií. Databáza nájde recenzie, ktoré sú významovo najbližšie. Napríklad pasáže, kde ľudia opisujú, že „značka X zlepšila trávenie psa“ alebo „značka Y má dobrý pomer ceny a kvality“.
- Poslanie dát do jazykového modelu (LLM)
- Príprava dát: Vybrané recenzie sa spracujú tak, aby ich jazykový model vedel jednoducho použiť. Môže to znamenať skrátenie príliš dlhých textov alebo ich zosumarizovanie.
- Integrácia: Takto pripravené pasáže sa pridajú k pôvodnej otázke a pošlú sa do jazykového modelu (napr. ChatGPT). Model tak získa aktuálne a konkrétne fakty z recenzií, ktoré sám v tréningu nemusel poznať.
- Generovanie odpovede jazykovým modelom
- Tvorba odpovede: Jazykový model spojí svoje všeobecné znalosti o výžive psov so získanými recenziami a zostaví odpoveď. Môže znieť napríklad:
„Podľa recenzií zákazníkov sa ako najlepšie hodnotí značka X, ktorá psom zlepšuje trávenie. Často sa spomína aj značka Y, ktorú chvália pre dobrý pomer ceny a kvality.“ - Doladenie a výstup: Finálna odpoveď sa ešte upraví tak, aby bola zrozumiteľná a konzistentná, a následne sa odovzdá používateľovi.
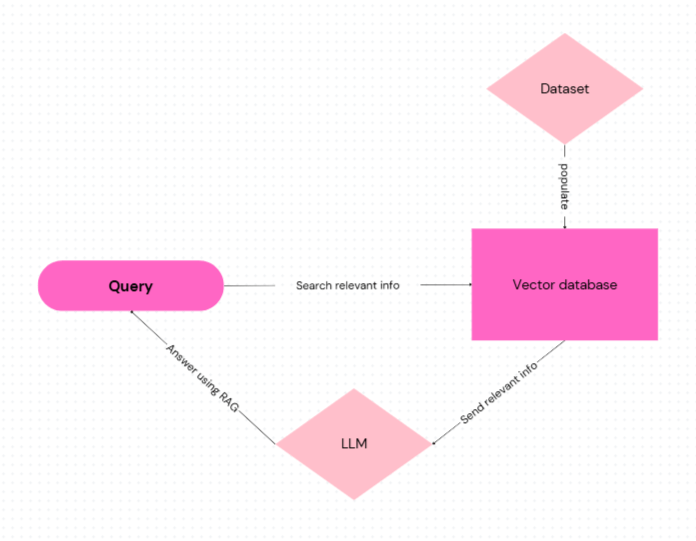
Takto AI funguje ako veľmi rýchly knihovník: nevie všetko sama od seba, ale vie okamžite nájsť správne police a podstrčiť vám tie knihy, ktoré obsahujú odpoveď. A keďže dokáže texty aj pekne zosumarizovať, podá vám výsledok tak, že ho nemusíte sami lúštiť.
Limity a budúcnosť embeddingov
Embeddingy sú základnou stavebnou jednotkou modernej umelej inteligencie. Dokážu previesť text, obrázky či zvuky do čísel a umožniť počítaču hľadať významové súvislosti.
No hoci sú veľmi silné, stále majú svoje obmedzenia:
- Strata detailov: embedding zachytí význam, ale nie všetky jemné nuansy.
- Nejednoznačné slová: napríklad chladný môže znamenať teplotu aj povahu a model to nie vždy rozlíši.
- Starnutie modelov: staršie embeddingy nezachytia nové výrazy či trendy.
- Predsudky (bias): ak boli tréningové dáta zaujaté, model tieto predsudky zdedí.
- Výpočtová náročnosť: tréning vyžaduje obrovské množstvo dát a výkonu.
- Nedostatok špecializácie: všeobecné modely nie sú ideálne pre špecifické oblasti, ako je medicína či právo.
Výskum napreduje rýchlo a hľadá riešenia, ktoré tieto slabiny zmiernia. Pracuje sa na odstraňovaní predsudkov, na prepojení embeddingov s databázami faktov, na multimodálnych modeloch spájajúcich text, obraz aj zvuk a na efektívnejších metódach vyhľadávania.
To všetko má za cieľ urobiť embeddingy presnejšími a univerzálnejšími.
Embeddingy tak dnes tvoria most medzi ľudským jazykom a strojovým chápaním. Aj keď majú svoje nedostatky, každý rok sa zlepšujú a posúvajú nás bližšie k ideálu. V budúcnosti budú ešte presnejšie, univerzálnejšie, prispôsobiteľnejšie konkrétnym potrebám a zostanú jedným zo základných pilierov umelej inteligencie.
Zdroje
- https://huggingface.co/spaces/hesamation/primer-llm-embedding
- https://cloud.google.com/blog/topics/developers-practitioners/meet-ais-multitool-vector-embeddings
- https://www.debutinfotech.com/blog/understanding-the-role-of-embedding-in-models-like-chat-gpt
- https://www.datacamp.com/blog/vector-embedding
- https://zapier.com/blog/vector-embeddings/
- https://www.ibm.com/think/topics/vector-embedding
- https://www.tigerdata.com/blog/a-beginners-guide-to-vector-embeddings
- https://www.meilisearch.com/blog/what-are-vector-embeddings
- https://medium.com/thedeephub/vector-embeddings-in-rag-applications-9ea8043c172b
- https://cismography.medium.com/knowledge-bases-and-retrieval-augmented-llms-a-primer-c054db532b91
- https://wandb.ai/mostafaibrahim17/ml-articles/reports/Vector-Embeddings-in-RAG-Applications–Vmlldzo3OTk1NDA5
- https://www.pinecone.io/learn/vector-database/
- https://www.qwak.com/post/utilizing-llms-with-embedding-stores